Database Sharding: Solving Performance in a Multi-Tenant Restaurant Data Analytics System

A good problem to have
Tenzo is growing – fast. We’ve already done a lot of work improving the stability, performance and reliability of Tenzo, to make sure that your data is available fast and ready on time every day.
As part of that work, we launched our new Data Manager product, which makes sure our data gets in on time every time, we’ve rewritten our data summary framework (a set of background processes which are constantly recalculating what you need to know about any updated data), added new summary tables, released a new iPad compatible version of Tenzo, and spent a lot of time improving the performance of our API so that when you request data you’ll get it fast.
We’ve also added tonnes of smart new monitoring so that the engineering team can be alerted any time a customer’s requests take longer than expected.
We’re really proud of the products we’re building and how much value we can provide to restaurateurs but the growth we’re experiencing presents its own set of challenges to the engineering team. At Tenzo, we like to say these kinds of tricky scaling challenges are good problems to have.
As we added new integrations and onboarded new customers, we saw our growth accelerating so to prepare for the next phases we knew we would have to change how some of our backend processes work so we could keep providing the same service no matter how many customers we sign.
One of the biggest projects around scaling Tenzo was sharding our databases. In brief, this is where data are split across multiple databases and stored separately. This allows us to spread the query load across many database computers instead of one, reduces the interdependence between businesses, and enables us to scale without compromising on performance.
In addition to all of this, sharding is an important requirement for our enterprise clients – adding clean isolation of enterprise data to our existing strong access controls for added security, allowing direct access to the database to load additional data sources or run additional operational & accounting tools against their data in Tenzo, and enabling customers to make their own decisions about DB redundancy and multi-region availability.
In this blog we’ll be covering:
Why not just make it bigger?
Lots of things don’t scale linearly. If your restaurant has to produce twice as many sandwiches, doubling the size of everything in your kitchen isn’t going to solve the problem – you might need a bigger walk-in and a larger kitchen, but taller chefs or longer knives won’t necessarily help you.
Similarly, as we add more data to Tenzo, we can’t just keep increasing the size or speed of our database computers – it’s more sensible to add more databases and change how things work to operate in parallel. Splitting data across multiple databases in this way is called ‘sharding’ a database, with each database being referred to as a shard.
Splitting the database in this way has the added benefit of allowing us to decouple the speed one business gets their data from the activity of other businesses sharing their hardware, and enabling enterprise customers to have direct access to their own databases. Most of our databases use Postgresql, which can run into problems on very busy databases with Transaction ID wraparound and sharding also helps us to prevent this problem impacting services.
Of course before sharding Tenzo, we already had multiple databases – we had separate databases for customer data, incoming data which has not yet been processed, authentication service data, insight service data, and our own user analytics data. With thousands of tasks running against our customer database every hour, things could sometimes begin to slow down a little.
To help with this contention for the database, in addition to the primary databases, we also have read replica databases . These replicas are constantly streaming updates from the primary database (DB) and usually lag a few milliseconds behind the primary. Although this sounds fast, it’s not always fast enough to guarantee consistency of data for our background tasks, so while these background processes primarily read data from the primary DB, we serve most mobile app, web app, and API requests off read replicas to reduce contention on the primaries.
Summaries
We store detailed information about every item sold by our customers – sometimes thousands of sales per location per day – but when you click on Sales by Location, it’s important that you can see the headlines fast, without waiting on us to do complex math on all that data. To make sure we get you the answers you need, we precalculate everything we think you might need to know about your data before you ask for it. {% video_player “embed_player” overrideable=False, type=’scriptV4′, hide_playlist=True, viral_sharing=False, embed_button=False, autoplay=False, hidden_controls=False, loop=False, muted=False, full_width=False, width=’650′, height=’356′, player_id=’57372448543′, style=” %}
One way we do this is by using summary tables. These are complex SQL-based tasks which iterate through incremental changes to your data every few minutes, determining what facets of your data have changed, and recalculating everything we know about it.
By sharding our database, these summary tasks can operate in the context of a shard, decoupling the summaries of your business’s data from those of other tenants. One problem we occasionally would see before was that running a large bulk import for a new customer would sometimes lead to summaries being delayed for other businesses as summary tasks worked to keep up with all the changes. Each shard has its own tasks in the new world, so summaries are only limited by the businesses on the same shard.
Database Maintenance
Modern cloud-based databases abstract away a lot of the complexity that’s involved in operating on-premise infrastructure, but with busy production databases there are still maintenance tasks which are left to the operator.
In a sharded environment it is now much faster and simpler for us to run all of the vacuuming and analysis tasks we need to run. Since the datasets they’re running on are significantly smaller than before, these tasks can run in a lot less time and with fewer interruptions as we push new code or migrate.
Being able to schedule maintenance tasks for different shards at different times also helps balance demand across the day and run intensive tasks when dedicated shards are less busy.
Sharding Tenzo
So how do you go about scaling business analytics to a million locations? The most important things for us in this instance were maintaining a seamless, reliable, fast experience for our users, and building in flexibility and room to grow for us.
There are a few possible models we could have followed.
- Multiple Tenzo Deployments
- Separate Instances
- Shared Instances / Separate Databases
- Shared Instances / Separate Schemas
The Model
To give us the greatest flexibility in terms of the hardware that we provision, we decided to use a hybrid approach where we can arrange any number of businesses on shared or isolated schemas, across any number of database instances. This means we can locate a customer’s data on shared hardware initially and easily migrate it to provisioned hardware as you grow and your needs change.
Most of our backend code uses Django which abstracts away a lot of the complexity involved in connecting, querying, and updating data in our databases, but to shard our data we would need to update every piece of code that touches a database. With so many integrations, API endpoints, and periodic tasks over millions of lines of code, we needed to find an approach allowing us to minimise the developer effort involved which was easy to understand and difficult to get wrong.
Pinning & Database Router
Each time we access data in Django, the Django ORM can be configured to call a database router, providing contextual information like whether we are reading or writing, and what model we’re accessing.
We already used a database router to send much of our API traffic to read replicas to offload some of the pressure from our primary database. When we knew we weren’t writing data, we could first try requests against the read replica with failover to the primary if the query got terminated due to streaming replication.
In some situations, however, where we knew that replication lag could lead to bad or unexpected behaviours, we would “pin” the request thread to the primary database so the database router would send queries straight to the primary DB:
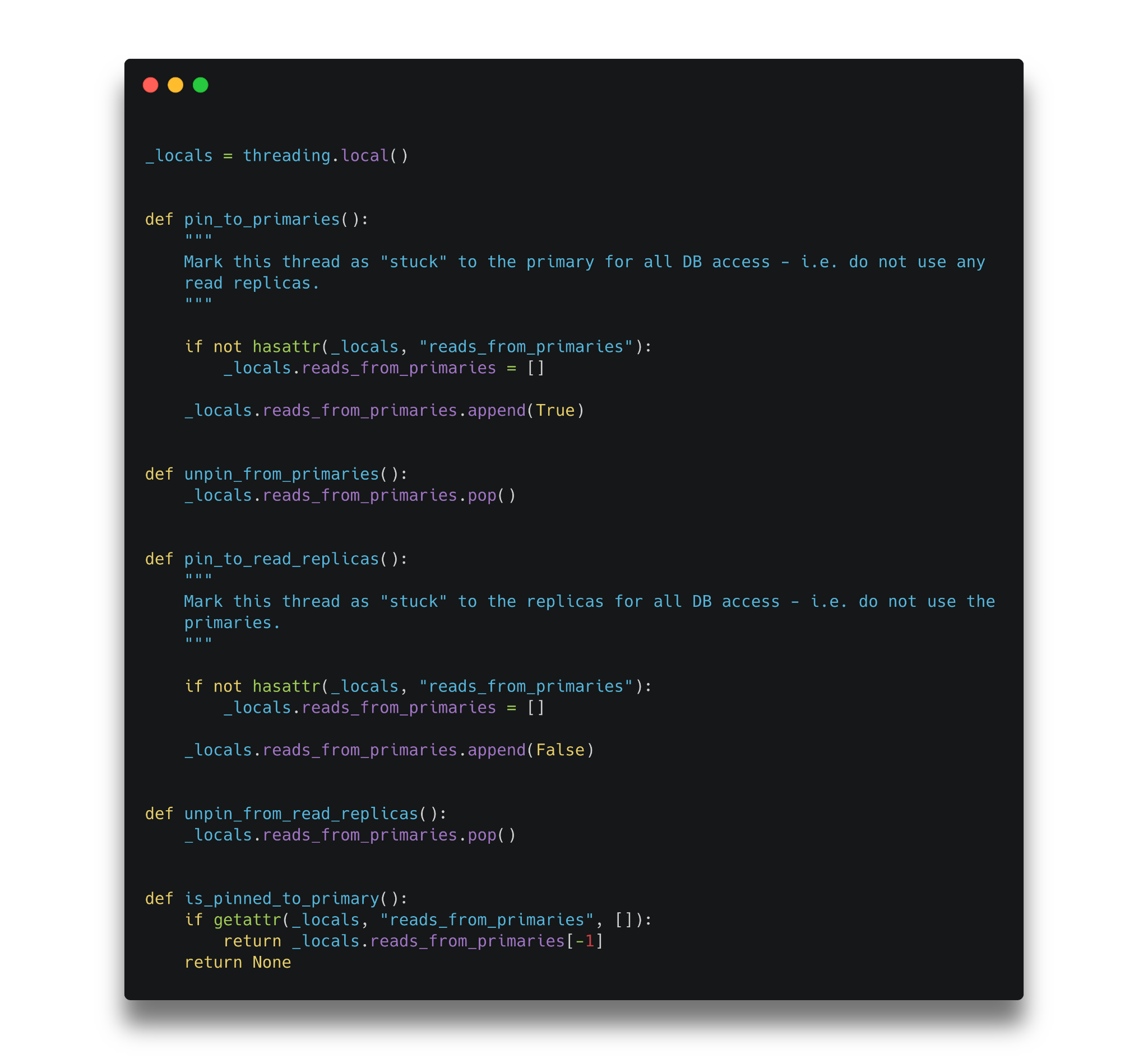
Previous read replica database router:
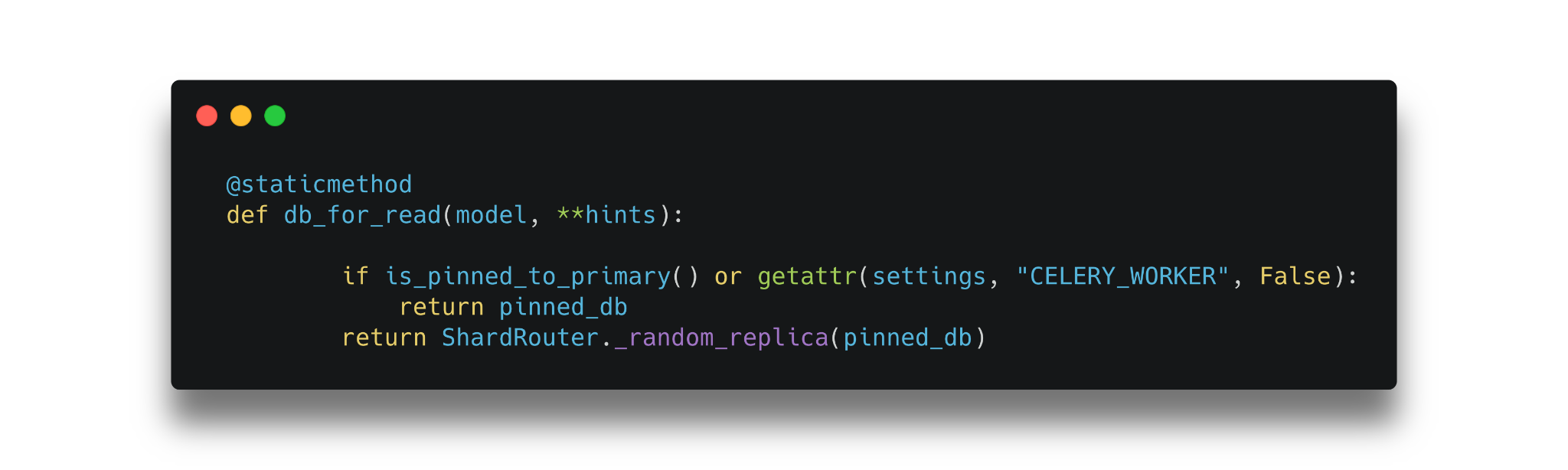
New database router:
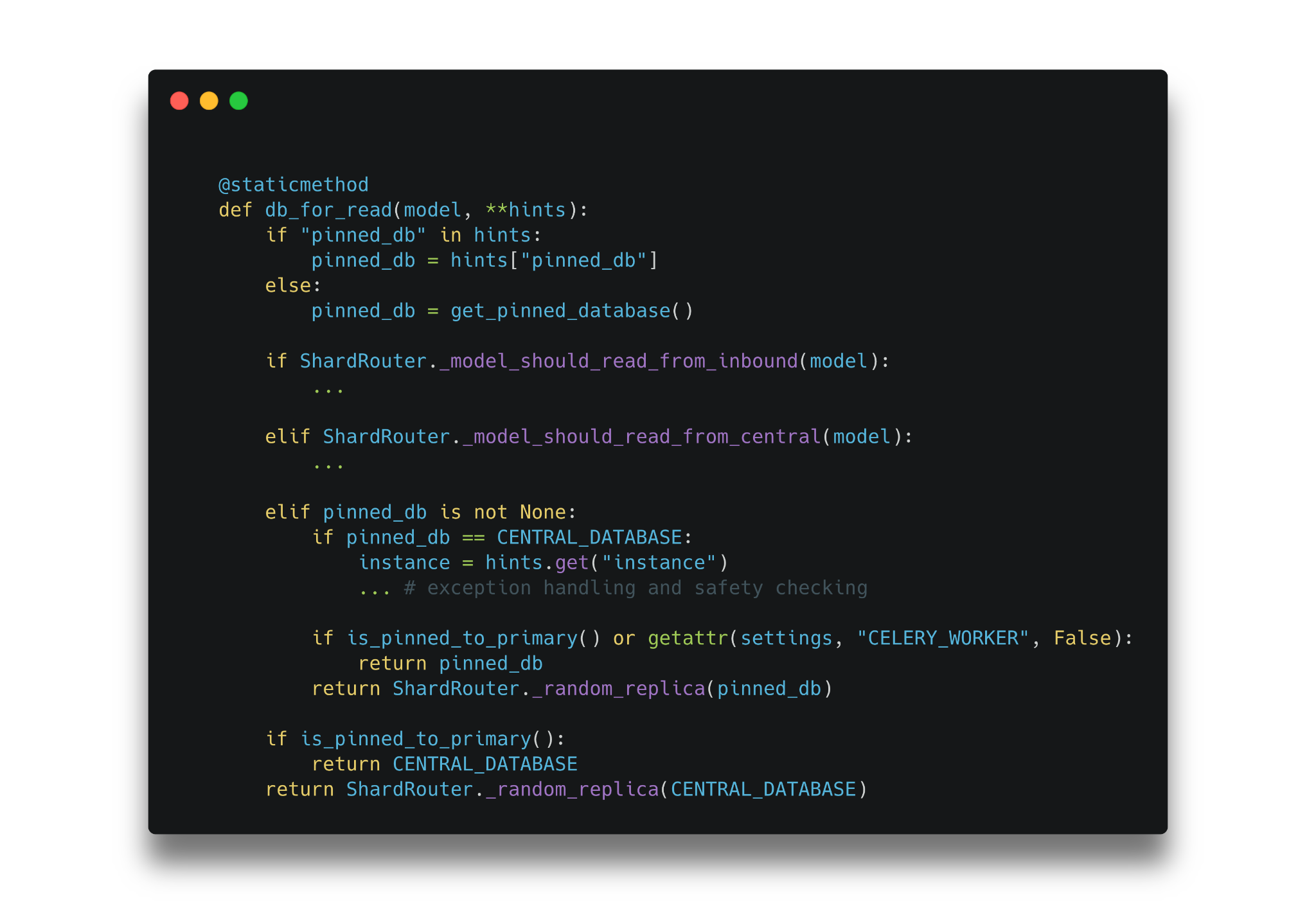
We extended this concept further to pin all incoming API requests to the shard hosting a user’s business in a Django middleware, and implemented context managers used to pin periodic tasks to the correct shard:
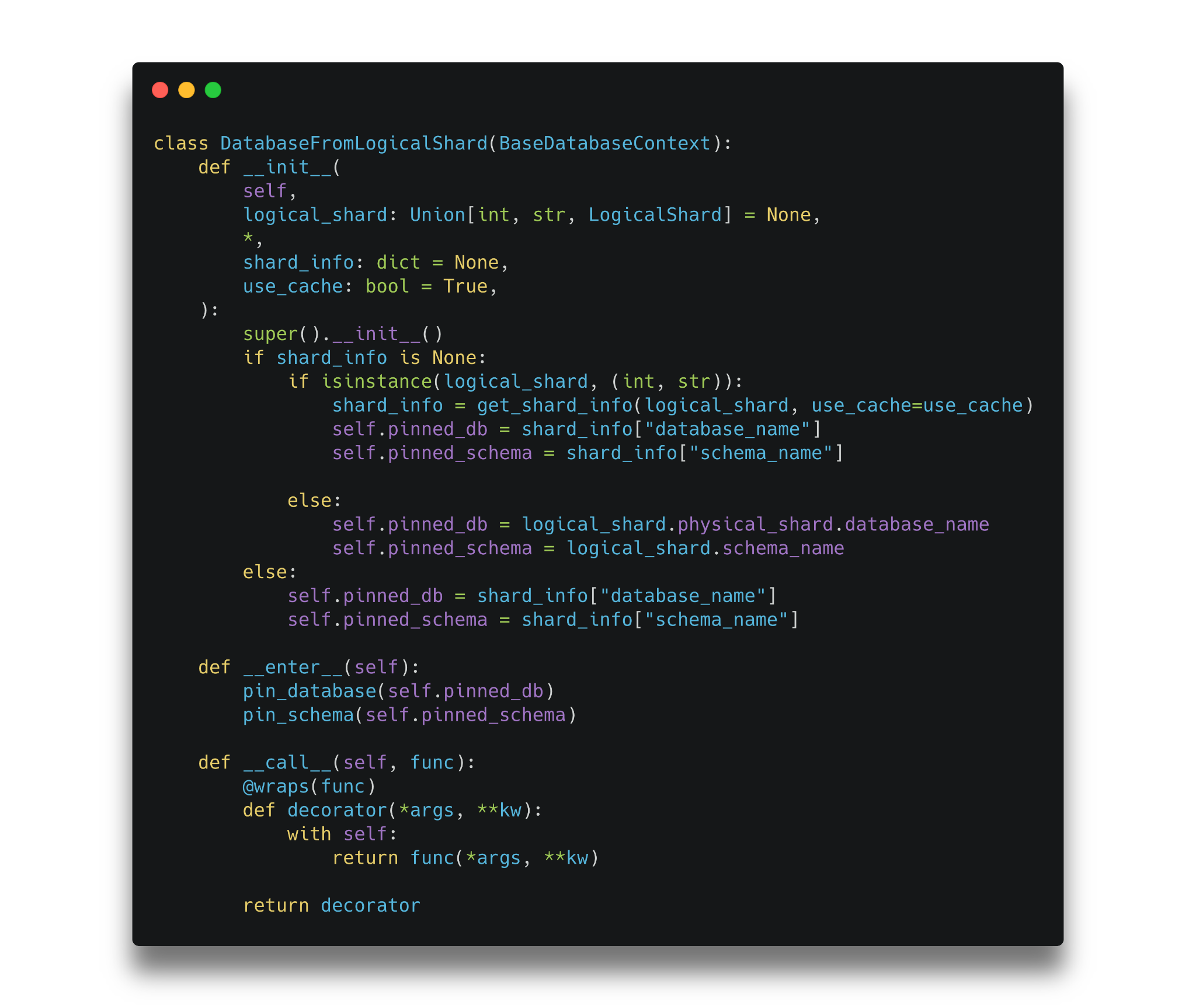
Reducing Touchpoints
It was important for us to minimise the engineering effort needed to write new code going forward too. To this end, we added a new Django middleware to automatically pin API requests to the correct shard so most API endpoints wouldn’t require context managers in their code.
Fortunately, almost all of our ETL code uses a common database loader, so there were very few updates required for the ETL code. Unfortunately, the full switchover to Data Manager happened during the development process and we had prioritised updating our legacy integrations so these were already done – demonstrating the challenge of rapidly changing priorities at a startup with a fast-moving codebase.
ID Schema & Generation
Before sharding, most database tables at Tenzo used unique 32-bit identifiers for every object. That means every sale, every item, every log entry had its own unique ID number, and for most tables, there were ~232 (about 4 billion) IDs available. Of course with the amount of data we import, we’d already reached this limit for some tables and moved some to use 64-bit IDs, but essentially every business’s data were using the same sequences to generate IDs.
One of our goals at the end of the process was to retain unique IDs for every object in Tenzo. This can help us to route requests quickly to the correct database but also makes for improved traceability.
However, we also wanted to plan for the future, and this meant making it easy for us to split shards in two, or “re-shard” the databases. This is so that if a growing customer on a multi-tenant shard decides they want direct DB access it’s fast and easy for us to separate their data out and we can also flexibly relocate data if needed.
To meet both needs while avoiding having to add a Business ID column to all of our tables, we decided to use the FK relationships between our models to generate IDs which include the business ID and the object ID.
In the new world, IDs are generated from business-specific ID sequences, with all tables using 64-bit IDs, where the 19 Most Significant Bits (MSB) encode the business ID in every ID, with 45 bits remaining for the object IDs, which on their own are unique only within a business.

By doing so, we can easily isolate rows by business without having to join between tables – e.g. for business ID 1000 we can simply select all rows where the ID is between (1000 << 45) and (1001 << 45).
But how could we avoid adding a column including the business ID to all the tables? Fortunately, this was quite easy. All customer sales, labour, and inventory data imported into Tenzo follows a strict schema, and links back to what we call a BAPI or BusinessAPIInstance – this is a link between a business and a Tenzo integration, and must have a foreign key to the Business table.
All child models have a path back to a BAPI through their parent models, and no orphaned child objects can exist in the DB. This means that when we are inserting, for example, a discount pertaining to a specific item on a sale, the item, sale, and location models will already exist in the database. Since these are all sharded models too, they will already include the business prefix in the MSB of their IDs.
With a little inspiration from Instagram’s sharding blog we created insert triggers on our tables to generate IDs using business-specific sequences and the business ID extracted from foreign-key columns on new rows.
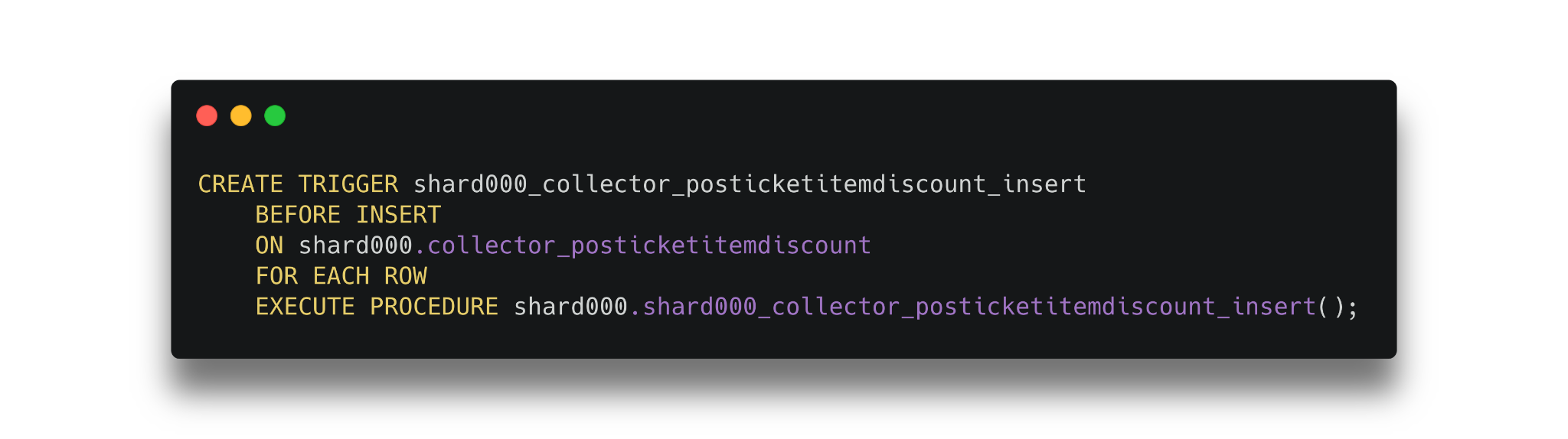
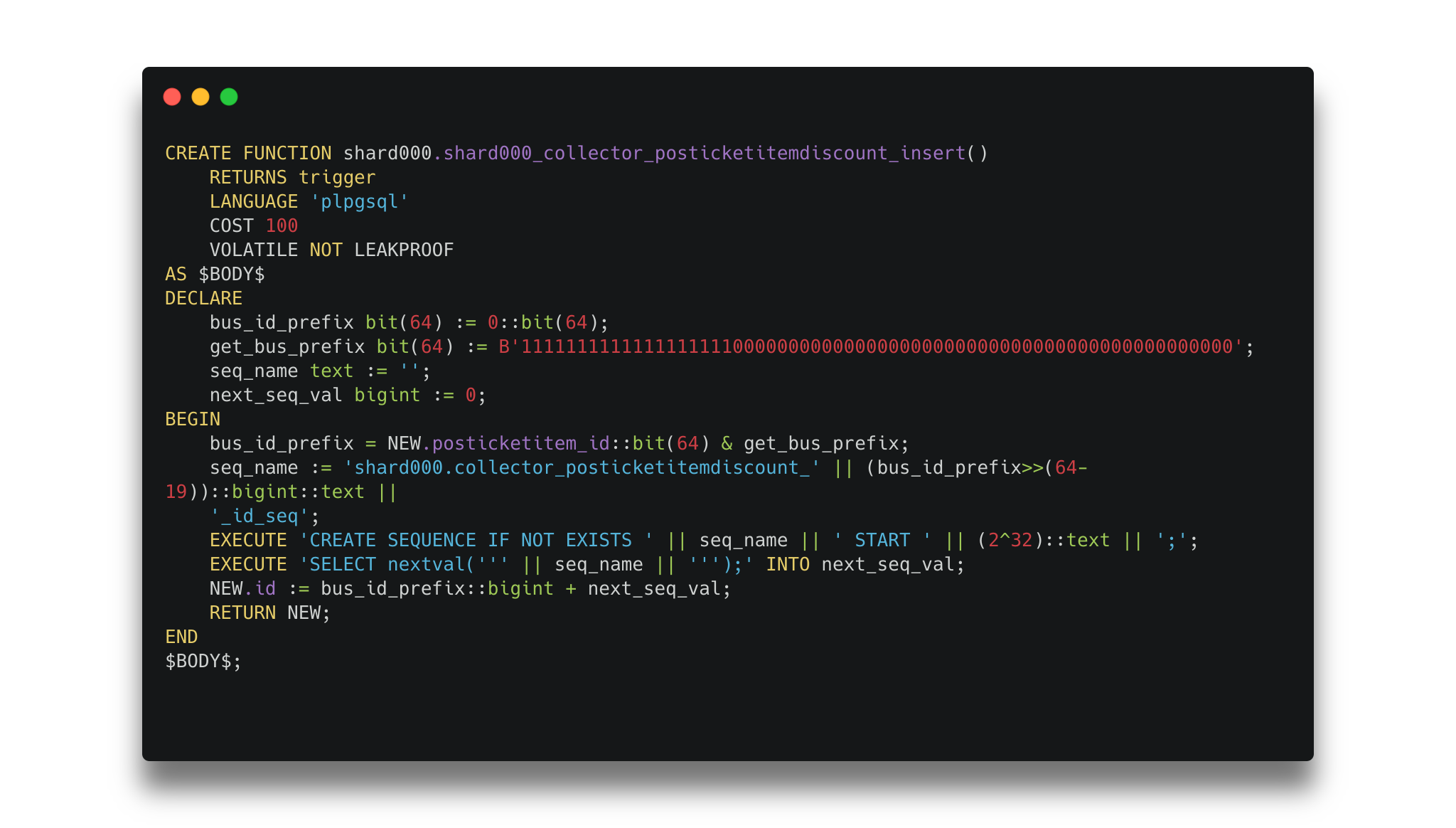
API Changes
Changing which models are stored on the same database, unfortunately, means updating a lot of code, and adds a little overhead to requests. Where previously we might try to select out all of the relevant data for a request in a single query, having data split across multiple instances means we sometimes need to run separate queries on different databases to collate everything we need.
We spent a lot of time optimizing API and administrative tooling to minimize the number of DB queries and in some cases sharding forced us to roll back that work. A good caching system helps to abate a lot of this however and with some extra tweaking, we’ve seen performance improvements across the board.
Planning for the Future / Outgrowing the Model
Although our sharding model removes some limitations and helps us scale, it does also introduce limitations of its own – e.g. having 19 bits for the business ID limits us to about half a million businesses in a single deployment. There is however scope to scale further with 128 IDs or multiple deploys, and what we’ve learned and implemented during this project will make that process a lot easier; reindexing all of our tables to 128 bits would be a fairly similar and more trivial exercise and require very few additional code changes.
Operational Considerations / Getting it Live
From the initial decision that prompted this project, we knew that it would be complex, all-encompassing, and time-consuming from both a development standpoint and an operational standpoint. Migrating database tables with many billions of rows takes time, and with the API changes rolled in, we would also need to add a bunch of new database indexes to keep everything running smoothly.
It’s all well and good designing a new system, but we also needed to keep the lights on while we updated all the data.
We ran many dry-run iterations of the process in a development environment long before the switchover happened. Our first ever test run took about 8 days to complete, meaning by the time the migrations were finished, the data would be 8 days out of date. We appreciate how crucial Tenzo is to our customers, however, so we set ourselves the goal of reducing the once-off downtime to 30 minutes or less.
Through a variety of careful code optimizations, database tuning, preparatory work, and temporary provisioning we managed to reduce the total time to migrate from 8 days down to about 10 minutes of downtime.
Migration Optimizations
Given the size, number, and complexity of our database indexes and constraints we realised early that it would be significantly faster to drop these at the beginning of the migrations and recreate them at the end – since we’d be working on an offline copy of production, we had the luxury of being able to do this, and there was no point continually updating indexes when we could create a fresh one in less time at the end. We also used this opportunity to review and condense our database indexing to make sure it was fit for the future.
Database Tuning
Across our dry runs, we modified a number of Postgres parameters including:
- work_mem
- maintenance_work_mem
- temp_buffers
- shared_buffers
- checkpoint_timeout
- checkpoint_completion_target
- max_wal_size
A full discussion of the reasons for these is beyond the scope of this blog, but further information on these params and more generally on tuning Postgres can be found here .
Provisioning
AWS really make this simple – we provisioned temporary RDS instances with huge provisioned IOPS and significantly higher CPU, memory, and network bandwidth. We ran dry-run parameter searches to optimise these, timing the process over many runs with various provisioning.
Data Manager
Having the vast majority of our integrations working in Data Manager made this whole process significantly easier – once the initial sharding and reindexing was done, we then needed to synchronize the new databases with changes from the live database. We developed once-off jobs to batch-replicate the latest changes from production, allowing us to select the latest imported blocks and re-import them to the new databases.
The only downtime we still needed was to ensure the latest user-submitted changes were replicated to the new environment (broadly things such as log submissions, events, user creation and deletion, permissions modifications, and adjusted forecasts).
QA, Deployment & Terraform
To make all of these changes easier to QA, we deployed full new deployments of Tenzo accessible only to the team, created a comprehensive manual QA plan, and even moved to a new deployment solution – using CircleCI with Terraform (look out for an upcoming engineering blog on why we chose these tools over competitors).
One of the great benefits of using Terraform is that we can more easily and flexibly spin up new dev environments according to our needs without having to spend time setting anything up manually.
In the end, we just had to push some changes to turn on maintenance mode, run our final replication script and switch our DNS records to point at the new load balancers.
Security Considerations
We take great care to maintain the security of your data in Tenzo; we operate a Bug Bounty Programme and perform regular security reviews, table-top threat simulations, and security-focused code reviews and use a variety of security and monitoring tools both operationally and as part of development.
Of course, opening up instances to external access for power users to run additional operational and accounting tools on top of Tenzo has some security implications. To mitigate this, externally available database instances exist in a secure environment & are unable to communicate with other databases, with tightly restricted networking and secure access controls to keep your data safe.
What We Learned
Sharding is hard! Especially on a mature and complex codebase. As things move so rapidly at Tenzo, the scope of a long-running project like sharding can change to accommodate updates from other projects.
The saving grace in this whole exercise was having extensive test coverage, which helped us keep track of what was left to do, and gave us good confidence in the performance and reliability of such sweeping changes to the codebase.
Dry runs helped us nail down the optimum processes, and having clear and detailed QA guides to use for sharding has helped inform improvements for our regular QA checks.
Especially for big projects, we’re lucky to have great support from the other teams at Tenzo, who are a great help with QA and testing, communicating with customers, and assisting in planning and developing solutions.
Last but not least, having a close-knit team of intelligent and capable developers with energy and enthusiasm for the business and who care deeply about the quality of the product is invaluable.
You may also like



